
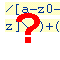 Reguläre Ausdrücke werden gern gemieden, da Sie einfach
Reguläre Ausdrücke werden gern gemieden, da Sie einfach
zu komplex sind. Dennoch lassen sich mit ihnen vielerlei Probleme
lösen. Wie man Reguläre Ausdrücke erstellt, und mit
PHP anwendet erfahren Sie hier.
Was sind reguläre Ausdrücke und wofür braucht man sie?
Reguläre Ausdrücke sind Muster (Patterns),
die auf eine Zeichenkette angewendet werden können, um beispielsweise
feststellen zu können, ob die Zeichenkette bestimmten Vorgaben entspricht
(nur Zahlen, zwei Wörter, etc.), oder um bestimmte Teile des Textes,
die zum Teil variabel sein können, zu ersetzen.
In diesem Tutorial wird erklärt, wie reguläre Ausdrücke aufgebaut
sind, was die Metacharaktere
(Zeichen mit spezieller Bedeutung) eines Patterns bedeuten, und
wie man das ganze in PHP umsetzt. Es werden nur die wichtigsten
Teile erklärt, für weiterführende Informationen findet sich am Ende
dieses Dokuments eine Linkliste.
Aufbau eines regulären Ausdrucks
Ein gewöhnliches Pattern besteht aus drei Teilen, deren Aufbau
an diesem Beispiel dargestellt werden soll:
/pattern/i
Die zwei Schrägstriche sind sog. Delimiter, die den Anfang und das Ende des Pattern kennzeichen.
Ein Delimiter darf aus jedem beliebigen nicht-alphanumerischen Zeichen
außer dem Zeichen “\” (umgekehrter Schrägstrich) bestehen, so z.B.
ein Ausrufezeichen oder ein Prozentzeichen.
Das Pattern an sich ist der Hauptteil, zu welchem wir
dann noch kommen werden.
Der letzte Teil besteht aus sog. Modifiern. Sie beeinflussen das
ganze Pattern – mehr dazu findet sich im übernächsten Abschnitt.
Reguläre Ausdrücke in PHP
PHP bietet mehrere Funktionen, in denen reguläre Ausdrücke zum
Einsatz kommen können. In diesem Dokument sollen nur preg-Funktionen
besprochen werden, da sie schneller als ereg-Funktionen sind und
die Patterns genauso in Perl und den meisten anderen Anwendungen,
die reguläre Ausdrücke unterstützen, benutzt werden können. Diese
Funktionen sind ab PHP 3.0.9 verfügbar. Die zwei wichtigsten preg-Funktionen
sind:
preg_match()
Syntax:
int preg_match (string pattern,
string subject [, array matches])
Verwendungsweise:
“pattern” enthält das Pattern, “subject” enthält die Zeichenkette,
auf die das Pattern angewendet werden soll. Der Rückgabewert
dieser Funktion ist 1, wenn das Pattern gefunden wurde, ansonsten
0. Ist der letztes Parameter “matches” (ein Array) angegeben,
so wird dieser mit Backreferences gefüllt – mehr dazu im Abschnitt
“Backreferences”.
preg_replace()
Syntax:
mixed preg_replace (mixed pattern, mixed
replacement, mixed subject [, int limit])
Verwendungsweise:
“pattern” enthält das Pattern, “replacement” enthält die Zeichenkette,
durch die das Pattern ersetzt werden soll. “subject” ist die
Zeichenkette, in der nach “pattern” gesucht und ggf. “replacement”
dafür eingesetzt wird. Der Rückgabewert der Funktion ist die
neue Zeichenkette. “limit” ist optional und kann angegeben werden,
um die Anzahl der Ersetzungen zu begrenzen.
Modifier
i
Dies ist der wohl am meisten gebrauchte Modifier. Bei regulären
Ausdrücken wird standardmäßig zwischen Groß- und Kleinschreibung
unterschieden – dieser Modifier schaltet dies aus.
s
Der s-Modifier veranlasst
den Parser dazu, die Zeichenkette, auf die der reguläre Ausdruck
angewendet wird, in einzelne Zeilen zu unterteilen – das Pattern
wird hierbei also nicht auf die ganze Zeichenkette bezogen,
sondern jede Zeile einzeln behandelt
m
Der m-Modifier ist das
Komplement zum s-Modifier:
Die Zeichenkette wird nicht in Zeilen aufgetrennt, sondern im
Ganzen behandelt.
Die Modifier können beliebig kombiniert werden, s und m zusammen machen
allerdings wenig Sinn.
Metacharaktere
Metacharaktere stehen für einen bestimmten Teil der Zeichenkette.
Die folgende Aufstellung zeigt deren Bedeutungen.
.
Der Punkt steht für jedes beliebige Zeichen, außer einem Zeilenumbruch,
wenn der m-Modifier nicht explizit angegeben wurde.
Beispiel:
/./
Dieser Ausdruck trifft auf jede Zeichenkette
zu, die genau ein beliebiges Zeichen an irgendeiner Stelle enthält
–
sie trifft also auf alle Zeichenketten
zu, die nicht leer sind.
^
Der Zirkumflex steht für den Anfang der Zeichenkette.
Beispiel:
/^a/i
Trifft auf alle Zeichenketten zu,
die mit einem kleinen oder großen “a” beginnen.
$
Das Dollarzeichen ist das Gegenteil zum Zirkumflex, es steht
für das Ende der Zeichenkette.
Beispiel 1:
/a$/
Trifft auf alle Zeichenketten zu,
die ein kleines “a”
am Ende einer Zeile haben.Beispiel 2:
/a$/m
Trifft auf alle Zeichenketten zu,
die an ihrem Ende ein kleines “a” haben.
|
Dieses Zeichen wird verwendet, um Alternativen anzugeben (oder).
Beispiel:
/^a|b$/
Trifft auf alle Zeichenketten zu,
die aus genau einem kleinen “a” oder genau einem kleinen
“b” bestehen.
( )
Die runden Klammern können benutzt werden, um Teile des Patterns
zusammenzufassen und von anderen abzugrenzen.
Beispiel 1:
/^a(b|z$)/
Trifft auf die Zeichenketten “ab” und “az” zu.
Beispiel 2:
/^(a|b)(c|d)$/
Trifft auf die Zeichenketten “ac“, “ad“,
“bc” und “bd” zu.
Beispiel 3:
/^(a(b|c)|def)$/
Klammern können beliebig geschachtelt
werden, dieser Ausdruck trifft daher auf die Zeichenketten
“ab“, “ac” oder “def” zu.
[ ]
Die eckigen Klammern dienen zur Angabe von Zeichenklassen,
mehr dazu im entsprechenden
Abschnitt.
{ }
Die geschweiften Klammern dienen zur numerischen Angabe von
Zeichenanzahlen, wir werden sie im folgenden Abschnitt “Quantifier”
besprechen.
Soll ein Zeichen nicht als Metacharakter (hierzu zählt auch der
gewählte Delimiter), sondern als normales Zeichen aufgefasst werden,
so ist diesem Zeichen ein umgekehrter Schrägstrich (Backslash) voranzustellen:
Beispiel: /\(abc\)/
Dieser Ausdruck trifft auf jede Zeichenkette zu, die “(abc)” enthält.
Quantifier
Mit Quantifiern ist es möglich, eine minimale, maximale oder exakte
Anzahl für ein oder mehrere Zeichen festzulegen. Wir kein Quantifier
angegeben, so wird angenommen, dass das Zeichen genau einmal vorkommen
muss.
Standard-Quantifier sind:
*
Der Stern steht für Anzahlen von 0 oder mehr.
Beispiel:
/.*/
Trifft auf jede beliebige Zeichenkette
(auch eine leere) zu.
+
Das Pluszeichen steht für Anzahlen von 1 oder mehr.
Beispiel:
/a+/
Steht für eine Zeichenkette mit mindestens
einem “a“.
?
Das Fragezeichen steht für Anzahlen von 0 oder exakt 1.
Beispiel:
/^(abc)?$/
Steht für “abc” oder eine leere Zeichenkette,
nicht aber für “abcabc“.
{n}
Steht für eine Anzahl von genau
n Zeichen.
Beispiel:
/a{6}/
Steht für exakt
sechs “a“.
{n,}
Steht für eine Anzahl von mindestens
n Zeichen
Beispiel:
/a{1,}/
Steht für mindestens ein
“a”und ist somit äquivalent
zu den Ausdrücken/a/und/a+/.
{n,m}
Steht für eine Anzahl von mindestens n, aber höchstens m Zeichen.
Beispiel:
/a{2,4}/
Trifft auf alle Zeichenketten zu,
die 2, 3 oder 4“a”hintereinander haben.
Standardmäßig versuchen die Quantifier, auf einen so großen Text
wie möglich zu passen. Dies kann zu Problemen führen: Angenommen
es liegt eine Zeichenkette $str = “[b]text[/b]text[b]text[/b]”
vor, und wir möchten daraus “<b>text</b>text<b>text</b>”
machen. Versuchen wir es folgendermaßen:
$str = preg_replace(“!\[b\](.*)\[/b\]!”,”<b>text</b>”,$str);
so erhalten wir als Ergebnis “<b>text[/b]text[b]text</b>”
– nicht ganz das, was wir wollten. Um dieses Verhalten abzustellen,
setzen wir hinter den Quantifier ein Fragezeichen “?”:
$str = preg_replace(“!\[b\](.*?)\[/b\]!”,”<b>text</b>”,$str);
und das gewünschte Ergebnis ist erreicht! Jeder der oben beschriebenen
Quantifier kann durch ein angehängtes “?” zu diesem Verhalten
bewegt werden, so z.B. {1,4}? oder +?.
Charakterklassen
Eine Auswahl von erlaubten Zeichen kann in eckigen Klammern angegeben
werden:
/^a[bc]$/ trifft beispielsweise auf “ab” oder
“ac” zu.
In einer Charakterklasse haben zwei Zeichen eine Sonderbedeutung:
Ein vorangestelltes “^” bedeutet in diesem Kontext eine Negierung
der angegebenen Zeichen – man kann auch sagen, dass dann nur die
komplementären Zeichen gelten.
/^a[^bc]$/ trifft also auf alles außer “ab”
und “ac”zu.
Das zweite Zeichen mit Sonderbedeutung ist der Bindestrich “-“.
Zwischen zwei Zeichen eingesetzt, gibt er eine Reichweite an. Beispiele
hierzu:
/^[a-zA-Z]+$/ trifft also auf alle Zeichenketten mit
Groß- und Kleinbuchstaben, aber ohne Zahlen zu.
/^[a-Z]+$/ bewirkt
das gleiche, ist jedoch aufgrund der unterschiedlichen Zeichendisponierung
bei verschiedenen Systemen unsicher.
Backreferences
Backreferences sind Rückbezüge, sie beziehen sich also auf einen
vorangegangenen Teil des Patterns (in runden Klammern) und enthalten
deren Inhalt. Es gibt zwei Syntaxes, die neuere davon ist $n,
wobei n für die n-te Klammerngruppe steht.
Beispiel:
!(<b>|<i>)(.*?)(</$1>)!
trifft auf “<b>text</b>”
und “<i>text</i>”
zu, aber nicht auf
“<b>text</i>”
Am nützlichsten sind Backreferences jedoch bei Ersetzungsoperationen
mit preg_replace():
$str = preg_replace(“!-anfang-(.*?)-ende-!”,”<anfang>$1<ende>”,$str);
Dieses Konstrukt würde also z.B. die Zeichenkette “-anfang-text hier-ende-“
durch “<anfang>text ersetzen.
hier<ende>”
Erweiterte Patterns
Erweiterte Patterns bestehen aus runden Klammern, einem Fragezeichen
am Anfang, einem dem Fragezeichen folgenden Operator ound dem Pattern
xxxan sich: (?oxxx)
Die nützlichsten hierbei sind:
(?:xxx)
Verhält sich wie eine normale Klammerngruppe, erzeugt jedoch
keine Backreference.
Beispiel:
/(?:ab)(cd)/
$1enhält nun die Zeichenkette
“cd”.
(?!xxx)
Negiert das angegebene Pattern und wirkt sich auf das vorangehende
aus.
Beispiel:
/text1(?!text2)/
Trifft auf eine Zeichenkette zu,
die“text1”enthält, aber kein“text2”danach.
(?<!xxx)
Negiert das angegebene Pattern und wirkt sich auf das nachfolgende
aus.
Beispiel:
/(?<!text1)text2/
Trifft auf eine Zeichenkette zu,
die“text2”enthält, aber nur, wenn“text1”nicht
davor kommt.
Anwendungsbeispiele
Postleitzahlencheck (Deutschland)
Ein sehr einfaches Beispiel. Eine deutsche Postleitzahl besteht
immer aus genau 5 Ziffern:
/^[0-9]{5}$/
eMail-Adressencheck
Hierzu lassen sich recht komplexe Ansätze entwerfen. Eine eMail-Adresse
darf nur aus Buchstaben, Ziffern, Bindestrichen, Unterstrichen,
Punkten und einem“@”als Trenner bestehen. Die Toplevel-Domains
sind ebenfalls festgelegt.
Fangen wir also mit einem
“@”als Trenner und den erlaubten
Zeichen davor und danach an:
/[\.a-z0-9_-]+@[\.a-z0-9-]+/i
[Bemerkungen:
1) Die Kleinbuchstaben reichen aus, da wir ja den i-Modifier
angegeben haben
2) Der Bindestrich muss hier auch nicht extra maskiert werden,
da er am Ende der Charakterklasse steht.]
Nach dem
“@”dürfen allerdings keine Punkte oder Unterstriche
sein – genausowenig wie ein Punkt direkt am Anfang der Adresse
– also verbieten wir sie dort und bauen noch die Domains ein:
/[a-z0-9_-]+(\.[a-z0-9_-]+)*@([0-9a-z][0-9a-z-]*[0-9a-z]\.)+([a-z]{2,4}|museum)/i
Zeilenumbrüche konvertieren
Linux/Unix, der MacIntosh und Windows haben verschiedene Zeilenumbrüche:
- Linux/Unix:
\noder\012in Oktalschreibweise
- MacIntosh:
\r\015in Oktalschreibweise
- Windows:
\r\noder\015\012in Oktalschreibweise
Es ist wünschenswert, diese zu vereinheitlichen – die Funktion
nl2br()
von PHP wandelt z.B. nur\nin HTML-Zeilenumbrüche (<br>)
um. Dies erreichen wir mit folgendem Konstrukt:
$str = preg_replace(“!(\r\n)|(\r)!”,”\n”,$str);
- Linux/Unix:
Dies war nun ein kleiner Ausschnitt aus den Anwendungsmöglichkeiten
von regulären Ausdrücken. Es gibt noch viele weitere – dies soll
jedoch dem Leser als Übung überlassen werden.