
 Das ER – Modell beschreibt die Beziehungen zwischen einzelnen Datensätzen und ist die wohl die wichtigste Grundlage für die professionelle Arbeit mit Datenbanksystemen und dem Datenmanagement. Dieser Artikel soll einen Einblick in die komplexen Beziehungen von Daten geben, und die einzelnen möglichen Relationen anhand von Beispielen zeigen.
Das ER – Modell beschreibt die Beziehungen zwischen einzelnen Datensätzen und ist die wohl die wichtigste Grundlage für die professionelle Arbeit mit Datenbanksystemen und dem Datenmanagement. Dieser Artikel soll einen Einblick in die komplexen Beziehungen von Daten geben, und die einzelnen möglichen Relationen anhand von Beispielen zeigen.
Um erfolgreich ausgefeilte Datenbanksysteme zu erstellen benötigt
man das wissen über die Grundkonzepte von Datenbanken. Zuerst
sollte man klären was überhaupt eine Datenbank ist, und
wozu diese benötigt wird.
Eine Datenbank ist eine Sammlung von Objekten (Daten). Diese Daten
sind in Tabellen untergebracht, ein Datenobjekt kann eine Anweisung,
eine Verknüpfung oder einfach nur ein Text sein. Eine Datenbank
kann beliebig viele Tabellen haben.
Die Tabellen, in denen die Daten gespeichert sind werden durch Spalten
und Reihen dargestellt, was die strukturelle Verteilung deutlich
macht. Eine komplette Reihe einer Datenbanktabelle wird als Datensatz
betrachtet. Die Anzahl der Spalten ist hier verantwortlich für
die Länge des Datensatzes.
Ein Feld ist eine bestimmte Spalte aus einem Datensatz.
Die folgende Darstellung soll die hier gemachten Definitionen nochmals
deutlich machen.
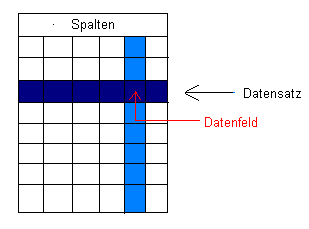
Aus der Abbildung kann man erkennen, wie man
nun auf einen einzelnen Datensatz zugreifen kann. Ein Datensatz
ist dadurch gekennzeichnet, das er einmalig ist, also nicht nochmals
vorkommen kann und unter gewissen Bedingungen nicht vorkommen darf.
Diese einmalige Kennzeichnung macht es möglich leicht auf diese
Daten zuzugreifen.
Aus unserem täglichen Leben kennt man diese Einmaligkeit,
wenn man unseren Personalausweis sieht. Dieser ist durch eine einmalige
Nummer fest definiert. Es gibt keinen Menschen, der einen Personalausweis
mit der gleichen Nummer hat.
Genau das machen Datenbanken. Durch die Festlegung eines einmaligen
Schlüssel, man spricht hier von einem Primärschlüssel
(Primary Key), kann ein Datensatz als einmalig definiert werden,
und mit dieser einmaligen Kennzeichnung auf diesen zugegriffen werden.
Was ist nun SQL?
Klar ist, das sich jetzt langsam die Frage stellt, was SQL überhaupt
ist, und wozu es benötigt wird. In SQL Abfragen kann man Befehlszeilen
und Anweisungen an den Server senden, gar kleine Programme schreiben,
doch Sinn macht das ganze erst, wenn die Datenbank mit Programmen,
wie PHP Skripten verbunden wird, worin das PHP Skript über
SQL auf die Daten in der Datenbank zugreift, und diese manipuliert
d.h. verändert.
SQL besteht aus strikten Regeln, die beschreiben, was z.B. eine
zulässige Befehlssyntax ist, oder welche Inhalte für Felder
verwendet werden. Jede Spalte kann nur mit Daten gefüllt werden,
die dem zulässigen Datentyp entsprechen. Ich kann also keinen
Text für eine Ganzzahl (Integer) einsetzen. Die Indexe, also
die Schlüssel beschleunigen den Zugriff auf die Daten durch
Such- und Sortierfunktionen.
Das relationale Model beschreibt die Beziehungen zwischen den einzelnen
Daten. Schon bei der Wahl der Tabellenstruktur wird man mit diesem
System aus Beziehungen konfrontiert.
Das folgende Beispiel eines kleinen Hardware – Shops zeigt
im kleinen einfache Beziehungen.
| Artikel – ID |
Kategorie – ID |
Name | Beschreibung | Preis |
| 1 | 1 | AMD Athlon 1,2 GHz |
Der AMD Athlon mit 1,2 GHz gehört zu den leistungsstärksten CPU’s die zur Zeit auf dem Markt sind. |
150,99 € |
| 2 | 1 | Pentium 4 1,5 GHz |
Der neue P 4 von Intel, noch schneller noch besser! |
250 € |
| 3 | 2 | Western Digital FP 40 GB |
Die 40 GB Festplatte von Western Digital, mit einer Zugriffszeit von 8,5 ms. Unschlagbar günstig! |
200 € |
| 4 | 3 | 128 MB DDR-RAM |
128 RAM Arbeitsspeicher mit neuester DDR-Technologie. |
60 € |
Zunächst müssen wir festlegen, worin die Beziehungen liegen.
Der einmalige Schlüssel ist hier die Artikel – ID. Mit
dieser kann man auf die weiteren Daten des Artikels zugreifen. Der
nächste Schlüssel ist die Kategorie – ID. Hier finden
wir auch schon die erste Beziehung. Mit der Kategorie – ID
wird festgelegt, in welche Kategorie ein Artikel gehört. In
unserem Beispiel sind das Prozessoren, Festplatten und RAM –
Bausteine. Die Daten, wie jetzt die Kategorie heißt, oder
welche Beschreibung es allgemein zu der Kategorie gibt, welche Artikel
es gibt sind in einer anderen Tabelle gespeichert. Mit der Kategorie
– ID als Primärschlüssel kann man auf diese Daten
zugreifen.
Die Tabelle mit den Kategorien könnte wie folgt aussehen:
| Kategorie – ID |
Name | Beschreibung |
| 1 | Prozessoren | Hier finden Sie unsere Produktpalette an CPU’s verschiedenster Taktung und Hersteller. |
| 2 | Festplatten | In diesem Bereich finden Sie alle Festplatten aus unserem Lager. |
| 3 | RAM – Bausteine |
Hier finden Sie Arbeitspeicher… |
Wie Sie sehen hat man nach dem ER – Modell (Enity Relationship)
Beziehungen zwischen den einzelnen Tabellen und Datensätzen
erzeugt. Diese Beziehungen sind nicht immer deutlich, doch es erscheint
logisch, die Daten so fein wie nur möglich zu verteilen, und
anhand eines Schlüssels auf diese Zuzugreifen.
Es ist auch nur praktisch die Daten so zu verteilen. Fügt man
in die obige Artikel-Tabelle auch noch die Daten der Kategorien
ein, und will später diese Daten der Kategorien ändern,
dann muss man die Daten für jeden einzelnen Artikel der dieser
Kategorie angehört, ändern. Das wäre natürlich
viel zu Umständlich.
Bei dieser Verteilung der Daten spricht man von der „Normalisierung“
von Daten, dies erfolgt nach den Regeln die anhand des Beispiels
gezeigt wurden.
Was für Beziehungsformen gibt es?
Das Beispiel hat eine einfache Beziehung zwischen den Daten aus
zwei Tabellen gezeigt. Man spricht hier von einer n – 1 Beziehung.
In der Tabelle der Kategorien wurden die Daten der Kategorie gespeichert,
diese sind direkt mit den Artikel-Daten aus ihrer Tabelle verknüpft,
da in beiden Tabellen jeder Datensatz eindeutig (Primärschlüssel)
zugeordnet ist. Doch können in der Artikel-Tabelle die Kategorie-ID
bei vielen Artikel gleich sein, dennoch ist jeder Eintrag in der
Kategorie-Tabelle einmalig. Deshalb spricht man hier von n –
1, da auf der linken Seite der Schlüssel mehrfach auftauchen
kann.
Doch es gibt neben dieser n – 1 Beziehung noch zwei weitere Beziehungsarten.
Zunächst wollen wir ihnen die 1-1 Beziehung vorstellen.
Die 1:1 Beziehung besteht zwischen zwei Tabellen, die jeweils Daten
einer ID-Speichern. Hier werden in der zweiten Tabelle z.B. Daten
eines Artikels gespeichert, die nicht unbedingt notwendig sind.
In einer Artikeldatenbank eines Shops können das die Support-Kontakte
oder die Garantie usw. sein. Diese Daten haben in beiden Tabellen
den gleichen Schlüssel, da sie ja zum gleichen Artikel gehören.
Man spricht hier von der 1-1 Beziehung.
Nun wollen wir uns der letzten möglichen Beziehungsart zuwenden.
Die n – n Beziehung. Sie entsteht wenn die Normalisierungsregeln
nicht komplett angewandt wurden. Ein Beispiel.
Ein User bestellt in einem Shop mehrere Artikel gleichzeitig. Er
erhält dafür eine Bestellnummer. Diese Bestellnummer ist
für alle Artikel gleich, da sie ja durch eine Bestellung entstanden
sind. Doch die Bestellung wird jetzt in einzelne Datensätze
unterteilt. Jeder bestellte Artikel wird in einer Tabelle aufgeführt.
Hier sind dann die User-ID (ID des Käufers) und die Artikel
– ID gleich, und diese Gleichheit tritt unter jedem weiteren
bestellten Artikel, einer Bestellung, des gleichen Artikels auf.
Hierbei handelt es sich um eine n – n Beziehung.
Die Nachvollziehung, speziell die der n – n Beziehung ist sehr
schwer, deshalb sollte man sich das bildlich vorstellen. Die Tabelle
in der die Bestellungen unseres Hardware-Shops gespeichert sind,
sieht wie folgt aus.
| Bestellungs – ID (pro Artikel) |
Kunden – ID |
Bestellnummer | Artikel – ID |
| 1 | 1 | 4 | 2 |
| 2 | 1 | 4 | 3 |
| 3 | 1 | 4 | 4 |
Wenn man die Beziehungen hier nachvollzieht herrscht die n –
n Beziehung zwischen der Kunden – ID und der Bestellnummer.
Wer jetzt aus den vorherigen Artikel die Bestellung des Kunden mit
der ID = 1 nachvollzieht kann man feststellen, das er unter der
Bestellnummer 4 auf einmal die Artikel mit der ID 2, 3 und 4 bestellt
hat, das wären ein Prozessor, eine Festplatte und ein RAM Baustein.
Dieses komplexe Beispiel, welches noch sehr abgespeckt ist, hat
sie nun in das ER – Modell eingeführt, und soll eine gute
Grundlage für das weitere Arbeiten mit professionellen Datenbanksystemen
unter SQL sein
(tf)